From Dokku to Komodo
Why I left Dokku
I ran Dokku for years and it was fine. git push dokku main, app deploys, done. That simplicity is exactly what Dokku is for, and for a single-app-per-host setup it is still one of the best answers in the self-hosted space.
The problem was me, not Dokku. As my side projects multiplied — a Rails trading bot, a mail server, a couple of shared databases, this blog — my Dokku host slowly turned into Dokku plus a pile of hand-rolled systemd units and docker run commands I was afraid to touch. That is a smell.
The thing that finally pushed me over the edge was observability. I wanted to glance at one screen and see: what is running, where, is it healthy, when did it last deploy, what changed. Dokku can answer most of that if you SSH in and run five commands. I did not want to SSH in.
Enter Komodo
Komodo is a self-hosted container management tool. You point it at a server, drop in a Docker Compose file, and it owns the lifecycle. It is not Kubernetes, it is not Nomad, it is not Portainer — it sits somewhere between a thin UI over compose and a lightweight control plane. For a homelab or a small fleet, that is exactly the sweet spot.
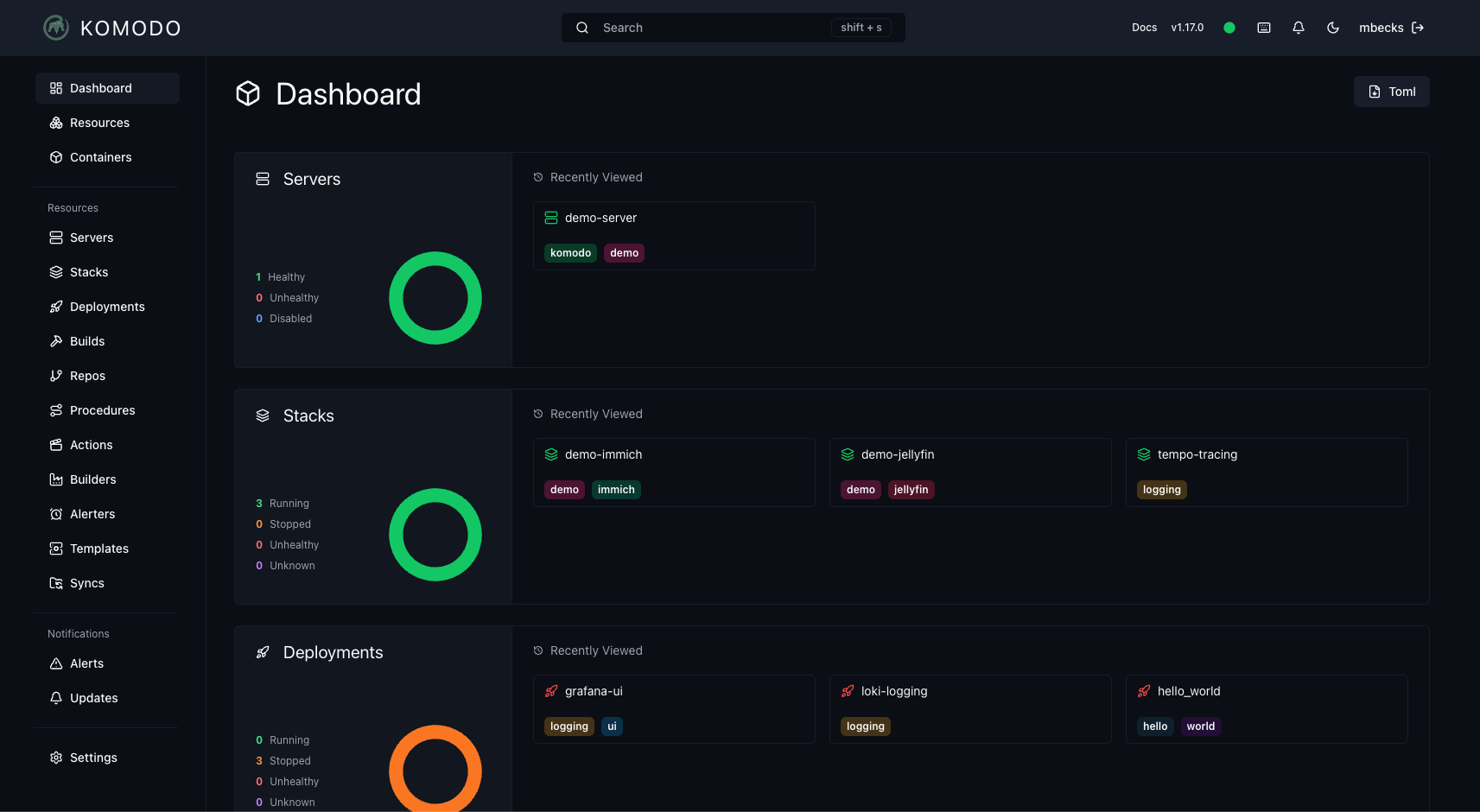
The mental model that clicked for me: a stack is a compose file, Komodo is the thing that remembers to deploy it.
The new shape
I split everything across two OVH boxes.
komodo (VPS)
The control plane. Small box, 6 vCores and 12GB of RAM. It runs:
- Traefik for HTTPS and Let's Encrypt
- MongoDB for Komodo itself
- Komodo Core — the UI and API
- A Periphery agent so the box can manage itself
- A daily MongoDB backup job that ships dumps to Cloudflare R2
komodo-worker-1 (Dedicated)
Where the actual workload lives. Xeon-D with 32GB of ECC and two NVMe drives — overkill for what I host, which is the whole point of running it yourself. It runs:
- Traefik on the edge
- PostgreSQL 18 and MariaDB 11.8 as shared databases
- Dragonfly as a Redis-compatible cache, 6GB, snapshots every ten minutes
- This Ghost blog
- Stalwart Mail for
mail.sebyx07.com - Claude Trader — a Rails app with Sidekiq and a Bun-based agent
- A small hCaptcha verifier service (hi, it just validated your signup if you joined the newsletter)
- Daily database backups to R2 with a 7-day retention
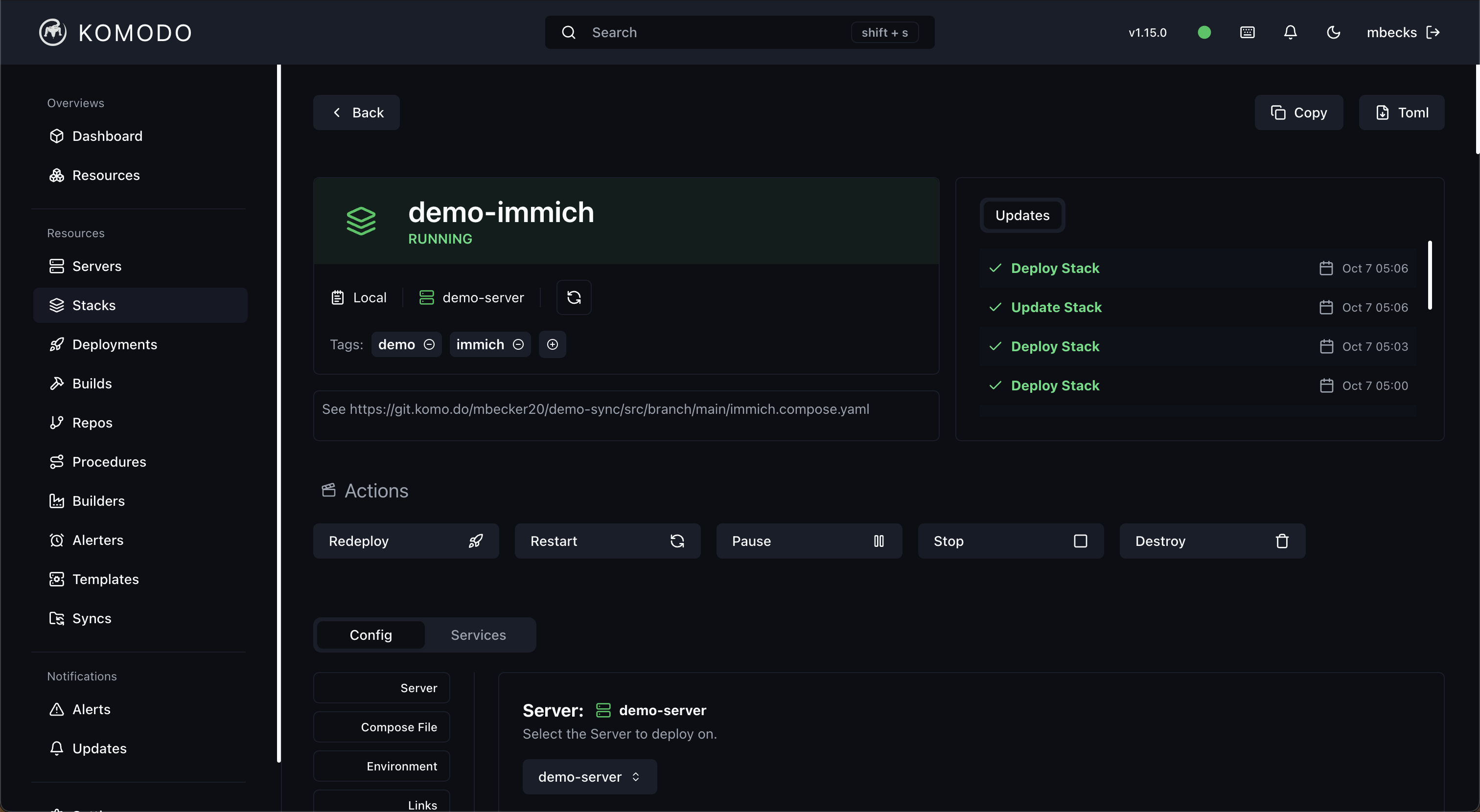
The whole thing is described in an infrastructure repo: YAML server configs, Docker Compose stacks, and a pile of TypeScript scripts in bin/ that wrap the Komodo, OVH, ClouDNS, and R2 APIs. If I lost both boxes tomorrow I could rebuild from that repo in an afternoon. I could not honestly say that about my Dokku setup.
The wins
Declarative stacks
Every service is a compose file checked into git. No more "what command did I run to get this container up." If I need to change memory limits on Postgres I edit the YAML, push, and click deploy. Komodo diffs what is running against what is declared and reconciles.
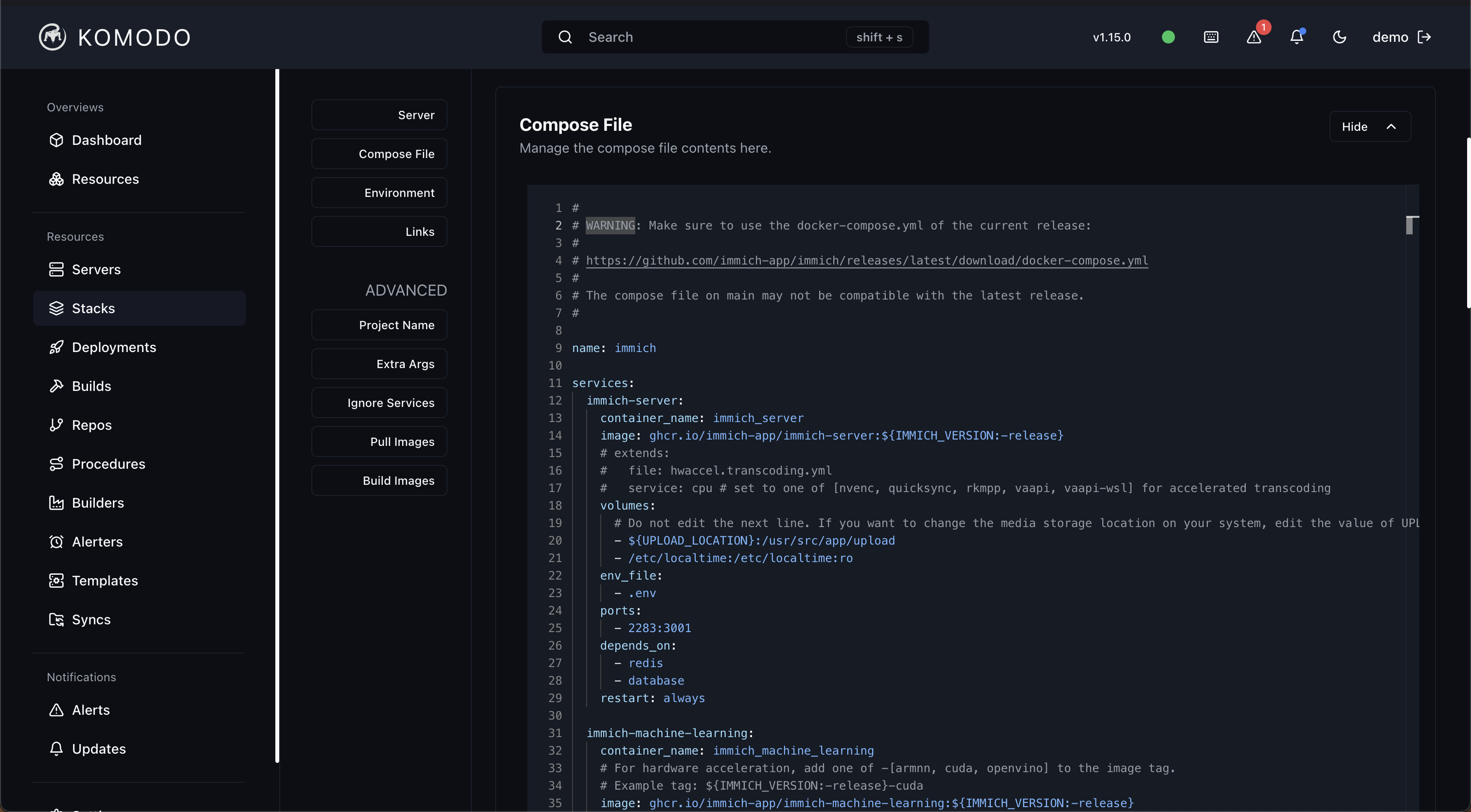
GitOps-ish, not full GitOps
I said "ish" on purpose. I do not want a ten-step PR pipeline for my personal infra. I want a repo as the source of truth and a deploy button I can hit from my laptop. Komodo does exactly that. Variables live in Komodo rather than in the repo, which keeps secrets out of git without needing sops or sealed-secrets ceremonies. Stack files reference them with [[VARIABLE_NAME]] and they are interpolated at deploy time.
One place to look
Stack list, per-service state, logs, update diffs, resource usage — all in one UI, and all exposed through an API I can script against. I wrote thin TypeScript wrappers so I can run npx tsx bin/komodo.ts stacks from my terminal and get a snapshot of everything. That is the observability story I wanted, and it cost me one evening.
Traefik in front of everything
Every service just opts in with a few labels and it gets HTTPS via Let's Encrypt, correct routing, and middleware for free. Dokku has its own solid nginx story, but wiring a brand-new app into Dokku's proxy versus adding four Traefik labels to a compose file is no contest once you have more than two services.
Backups I actually trust
Postgres, MariaDB, and Mongo all dump nightly to R2. One bucket, per-database prefixes, gzip'd. Retention handled by a scheduled job. I have restored from these dumps into a throwaway container and watched them come up clean, which is the only test that counts.
What I miss from Dokku
Honestly? The git push dokku main flow. There is something uniquely satisfying about deploying by pushing a branch. With Komodo I build images in CI, push to GHCR, then redeploy the stack. It is a better model for anything non-trivial, but it is a few more moving pieces for the tiny stuff.
I also miss how little I had to think about Dokku. Komodo asks me to think in compose files, networks, volumes, labels. That is the correct level of abstraction for what I am doing now, but it is not zero abstraction the way Dokku was.
Would I do it again
Yes, and I would do it sooner. The migration itself was the tedious part — exporting databases, re-pointing DNS, re-issuing certs, praying the mail server came back with its reputation intact. Once the dust settled I had a setup I actually understand end to end, described in a repo, managed from a UI, and backed up to object storage I do not own the hardware for.
For a homelab or a small indie stack, Komodo hits a rare sweet spot: powerful enough to not feel like a toy, simple enough that one person can hold the whole thing in their head. That is the bar I care about.